Observations
THE ANALOGY THAT FITS — RAILROADS, DOT-COMS, OR … SOMETHING WITH NO PRECEDENT
As usual, AI, as a new technology, goes through the Hype Cycle – and each camp, e.g. the user camp, the supplier camp and the investor camp has its own hype/bubble topics you can follow on the current platform of tech enthusiast.
Today, let me focus on the investor camp: The AI bubble debate has been running in the FT, the New York Times, and a steady stream of (Substack) analysts for at least eighteen months now. The pro-bubble camp points to capex and to the ratio between capex and visible revenue. The anti-bubble camp points to the speed at which that revenue is scaling — Anthropic reportedly above thirty billion in annualized revenue, OpenAI past twenty, hyperscaler cloud lines growing at twenty-five to thirty percent year-on-year. And between them, an overlapping group of people of the moat-and-value-capture camp argues that even if a correction comes, the right exposure — Nvidia, the hyperscalers, the leading foundation labs — will weather it because of structural moats.
We are skeptical of all three positions, not because they are wrong on their own terms, but because they all lean on a historical analogy that does not survive close inspection.
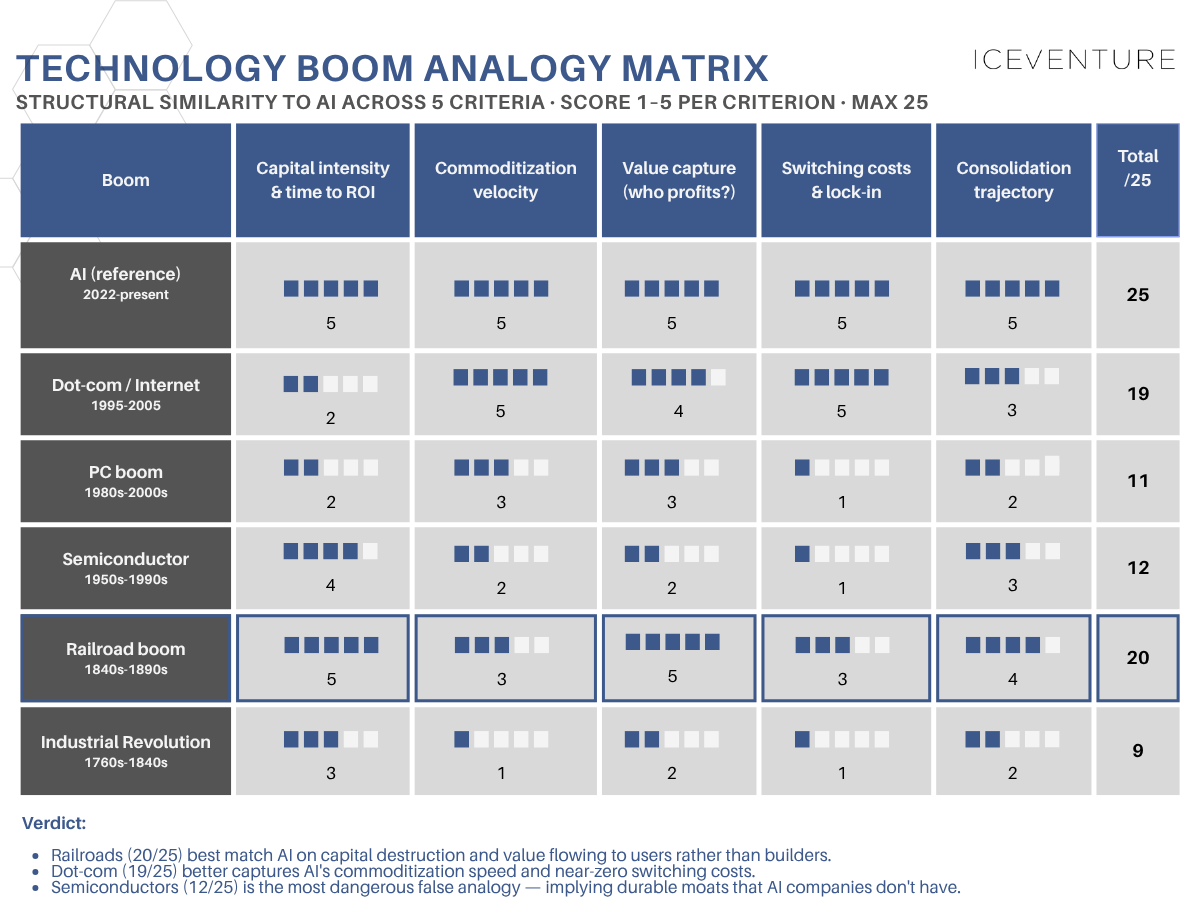
The exercise we have been running in client conversations, background rounds and internal workshops is straightforward — pick five dimensions that genuinely differentiate technology booms (starting with the industrial revolution) in ways that matter for investor outcomes, and score obvious past boom candidates against each other. Not surface similarities (every boom has a press cycle and an Elon-equivalent), but structural ones. In our final exercise, shared here, we logged in the following dimensions: capital intensity and time to ROI, commoditization velocity, value capture architecture, switching costs, and consolidation trajectory. We also included the value captures by users, meaning companies as an additional dimension, but feel free to choose your own dimensions. Then we discussed through past technology booms from the industrial revolution, over computers, chips, or other phases like the platform wars. The exercise produces an unwelcome result, out of which I outline three highlights, (playing the advocatus diaboli).
First, the railroad boom. Railroads were the last time a genuinely transformative technology consumed this share of available capital while systematically destroying returns for the people building it. The tracks delivered enormous social returns and meager private ones — investors lost their shirts, the economies built on top of the rails flourished. Some say it took the investor generation of Warren Buffet to capture meaningful (and systematically) returns. On capital intensity and value capture, AI maps onto railroads almost cleanly. Hyperscaler capex is now projected somewhere between six hundred and fifty and seven hundred billion for 2026, profitability is plausible only somewhere in the 2030s, and you can find good arguments the surplus is being captured by end-users (and a thin enabler layer of chip and power players), not by the people writing the cheques.
Second, the dot-com boom. Dot-coms got commoditization right in a way railroads did not, you could ironically say. Tracks took decades to become fungible across operators. A lot of once highly valued dot-com tech became quickly standard and services interchangeable. AI inference at the model layer is becoming substitutable in months — not fully, fine-tuning, agent tooling, evaluation infrastructure and proprietary data still create real switching cost. But enough that pricing power at the foundation-model layer evaporates faster than at any prior infrastructure layer in living memory. If you care about margin durability for AI model companies specifically, the dot-com analogy is the sharper one. And it is worth saying out loud — the people closest to the model layer, including Benedict Evans in his February essay, now openly describe foundation models as drifting toward commodity infrastructure sold at marginal cost. No wonder, implementations in May 2026 we see, speak of model agnostic structures.
Third — and this is the comforting analogy that gets the matter most wrong — semiconductors. Investors like the semiconductor framing because it implies that the infrastructure layer captures durable value through IP moats and qualification cycles. Nvidia equals Intel, and the rest takes care of itself. But semiconductors had multi-year design-in cycles, proprietary process technology that took tens of billions and decades to replicate, and customer lock-in measured in product generations.
AI has only a softer version of this at the chip layer — Nvidia's moat is real but narrower than the analogy flatters, given AMD's catch-up, custom hyperscaler silicon, and the inherent fragility of any single proprietary stack — and almost none of it at the AI model layer, where most current capital is going.
In other words, AI is a chimera. It combines railroad-scale capital intensity with dot-com-speed commoditization and dot-com-level switching costs at the layer where most of the spending happens. This specific combination has not appeared before in technology history (happy to discuss this), which is why every analogy limps. The implication is uncomfortable — capital may be destroyed even faster than in the railroads, because at least track took decades to become fungible, and even dot-com infrastructure had longer lock-in than the foundation-model layer does today.
The fact that hyperscalers are funding most of this from operating cash flow rather than external debt — the favored counter-argument — softens the systemic risk to the financial sector but does not change the underlying value-capture mathematics for the equity holders of those hyperscalers.
Back to the family-office / investor conversation. The honest portfolio question is not "which AI bet wins" but "what sits structurally above the commoditization curve" — applications with proprietary data and integration depth, regulated workflows where qualification still matters, distribution-locked verticals. The semiconductor analogy tells investors what they want to hear about moats that do not exist at the layer where most current AI capital is being deployed. This is the part of the consensus we keep pushing back on.
A longer theory I am happy to walk through case by case, but too long for a newsletter.
WHAT THIS MEANS FOR ENTERPRISE AI IMPLEMENTATION
The most useful conversation we are having with corporate and SME clients right now is not about which model to bet on. It is about how to design an AI implementation that does not embed a structural mistake at the architecture level — namely, building deep dependency on whichever lab happens to be ahead this quarter. The matrix above suggests three implications that we keep returning to in working sessions.
First, the model layer should be treated as substrate, not as strategy. If commoditization velocity at the foundation-model layer is approaching low switching costs in eighteen to thirty-six months, then any architecture that hard-codes one provider into the workflow is borrowing trouble. Model-agnostic orchestration, swappable inference, and evaluation infrastructure that benchmarks across providers are not nice-to-haves. They are the structural insurance against being on the wrong side of a price collapse — or, equally, being unable to switch when the next capable model launches at half the cost.
Second, the value sits in the integration layer, not in the prompt. The clients who are extracting durable productivity gains from AI are not the ones with the most sophisticated prompt libraries. They are the ones who have done the unglamorous work of cleaning their internal data, mapping the workflows where AI actually saves time (versus where it merely looks impressive in a demo), and building feedback loops that let domain experts correct outputs at scale. This is the part the consulting market is currently underpricing, partly because it is harder to sell than a "GenAI strategy" deck. We have seen mid-sized industrial companies get more business value from a six-week data-plumbing project than from twelve months of model experimentation.
Third — and this is the part that requires most pushback in client conversations — beware of paying frontier-lab prices for non-frontier work. A meaningful share of enterprise AI use cases (document classification, structured extraction, summarization, internal Q&A) does not need top-tier capability. The cost-per-token gap between frontier models and good-enough open or mid-tier models is one to two orders of magnitude in some workloads. A procurement discipline that asks "is this task actually frontier-bound, or are we paying for capability we do not use" tends to surface faster ROI than the alternative. And it has the additional benefit, given the matrix above, of reducing exposure to the layer where margins are most likely to be competed away.
The aggregate picture for an enterprise AI program in 2026 is, in our view, less heroic than the consulting decks suggest and more boring in the right ways. Multi-vendor by default. Data and workflow first, model second. Disciplined about which use cases justify which capability tier. The companies we see getting this right are mostly not the ones generating press coverage.
THE EUROPEAN POSITION — UNDERINVESTED, AND THIS TIME PROBABLY RIGHT
Europe has been mocked, including by parts of its own commentariat, for not producing a frontier AI lab. The German angle in particular — where the Mittelstand, the regulators and the state funding bodies all moved with their habitual deliberation — has become a running joke in transatlantic VC circles. We have been less convinced.
If the matrix above holds, the layer where Europe is structurally weak (frontier model training, hyperscaler capex) is also the layer where private returns are likely to be worst. The layer where Europe is comparatively stronger — applied AI in regulated industries, industrial process automation, vertical SaaS with deep integration into existing workflows — is precisely where the value capture architecture is least hostile to investors. Not a vindication of EU industrial policy, which is a separate and much messier conversation. But the reflexive conclusion that Europe "missed AI" assumes that the layer that gets capitalized is also the layer that gets paid. The matrix says it probably is not.
Coming up next...
But, as with many things in Europe it is complicated. The next edition will turn to a constraint that sits upstream of the financial arguments above: AI energy demand.
Total energy demand of AI is projected to grow fivefold by 2030, with AI workloads accounting for 24% of all datacenter capacity by the end of the decade. The energy cost arrives through two distinct vectors: direct operational consumption, sure, but also indirect grid costs — the structural electricity price increases driven by the explosive growth of AI datacenters competing for grid capacity, which affects all companies whether or not they use AI. The European electricity price differential adds a specific complication to the optimistic reading in the section above. More on all of this in the next issue.
Chart
Paul Kedrosky's "Honey, AI Capex is Eating the Economy" carries the chart that does the most work for the argument above — AI datacenter capex as a share of US GDP, plotted against the railroad buildout of the 1880s and the telecom buildout of the late 1990s (he uses 2020 on the chart). The visual punchline is that AI capex (represented by AI datacenter capex), at roughly 1.2 percent of US GDP and rising, has already passed the peak of the telecom buildout (around 1.0 percent) and is approaching one fifth of the railroad peak (around 6 percent), with the depreciation cycle on the AI assets dramatically shorter than on either of the older comparators.

Kedrosky's later note from March 2026 — that AI capex contributed essentially all of US Q4 2025 GDP growth — is the macro side of the same story. The chart is the single best one-page entry point for the bubble-vs-boom debate I have seen so far.
Readings
1 — David Cahn, Sequoia Capital, "AI's $600B Question" — the back-of-the-envelope calculation that started the serious capex-versus-revenue conversation in 2024. The frame has held up surprisingly well as the numbers have gotten worse. Read in combination with Cahn's January 2025 podcast appearance on Gradient Dissent, where he revisits the math after DeepSeek and Stargate.
2 — Jim Covello, Goldman Sachs, "Gen AI: Too Much Spend, Too Little Benefit?" — the canonical sell-side bear note. Covello's specific point that complex problems require capabilities current models do not have, and that costs may not decline as expected, is the strongest part. Useful as the reference point even if you disagree with the conclusion. Also interesting: Covello is in the camp arguing that the technology is structurally not designed for complex reasoning.
3 — Benedict Evans, "How will OpenAI compete?" — the most precise short essay on why the model layer looks structurally weaker than the foundation-lab valuations suggest. Evans's framing of foundation models drifting toward commodity infrastructure is the cleanest articulation of the dot-com side of the matrix above.
4 — Ben Thompson interview with Benedict Evans, Stratechery — the longer conversational version of the above. Worth it for the discussion of value capture and where it sits in the stack. Read it in combination with Evans's "AI eats the world" autumn 2025 deck.
5 — Paul Kedrosky, "Honey, AI Capex is Eating the Economy" — referenced above for the chart, but the surrounding analysis is also the cleanest macro framing of the AI buildout I have seen, with the right amount of caveat about depreciation cycles. His March 2026 note on AI capex carrying Q4 GDP growth is the natural companion piece.
6 — Sparkline Capital, "Surviving the AI Capex Boom" — the most disciplined value-investor framing of the cycle, with strong historical analysis of how prior capex booms have treated infrastructure shareholders. The capital-cycle argument they lean on (Edward Chancellor) is the one that should be sitting next to any AI portfolio review at a family office right now.


Schreibe einen Kommentar
Achten Sie darauf, die erforderlichen Informationen einzugeben (mit Stern * gekennzeichnet).
HTML-Code ist nicht erlaubt.