Osservazioni
L’ANALOGIA CHE FUNZIONA — FERROVIE, DOT-COM O… QUALCOSA SENZA PRECEDENTI
Come ogni nuova tecnologia, anche l'AI attraversa il suo Hype Cycle — e ciascun campo, ad esempio quello degli utenti, dei fornitori e degli investitori, ha i propri temi caldi che si possono seguire sulle piattaforme degli appassionati di tecnologia.
Oggi mi concentro sul campo degli investitori. Il dibattito sulla bolla AI va avanti sul Financial Times, sul New York Times e in una serie costante di analisti su Substack da almeno diciotto mesi. Il fronte pro-bolla punta il dito sui capex e sul rapporto tra capex e ricavi visibili. Il fronte anti-bolla sottolinea la velocità con cui quei ricavi stanno scalando — Anthropic riportata sopra i trenta miliardi di ricavi annualizzati, OpenAI oltre i venti, le linee cloud degli hyperscaler in crescita del venticinque-trenta percento anno su anno. E tra i due si colloca un gruppo trasversale — il fronte del moat e della cattura del valore — che sostiene come, anche in caso di correzione, le esposizioni giuste — Nvidia, gli hyperscaler, i principali lab fondazionali — reggerebbero grazie a moat strutturali.
Siamo scettici su tutte e tre le posizioni, non perché siano sbagliate in sé, ma perché tutte si basano su un’analogia storica che non regge a un’analisi approfondita.
L’esercizio che abbiamo condotto nelle conversazioni con i clienti, nei background round e nei workshop interni è semplice — scegliere cinque dimensioni che differenziano realmente i boom tecnologici (a partire dalla rivoluzione industriale) in modi rilevanti per i risultati degli investitori, e confrontare i principali casi storici su queste dimensioni. Non somiglianze superficiali (ogni boom ha un ciclo mediatico e un equivalente di Elon), ma strutturali. Nel nostro esercizio finale, che condividiamo qui sotto, abbiamo considerato: intensità di capitale e tempo al ritorno, velocità di commoditizzazione, architettura della cattura del valore, costi di switching e traiettoria di consolidamento. Abbiamo incluso anche la cattura del valore da parte degli utenti, cioè le aziende, come dimensione aggiuntiva. Abbiamo poi analizzato vari boom tecnologici dalla rivoluzione industriale, ai computer, ai chip, fino alle guerre delle piattaforme. Il risultato è scomodo, e ne evidenzio tre punti principali, facendo l'avvocato del diavolo.

Primo, il boom ferroviario. Le ferrovie sono state l’ultima volta in cui una tecnologia davvero trasformativa ha assorbito una quota così elevata del capitale disponibile distruggendo sistematicamente i rendimenti per chi la costruiva. I binari hanno generato enormi ritorni sociali e scarsi ritorni privati — gli investitori hanno perso, mentre le economie costruite sopra le ferrovie prosperavano. Alcuni sostengono che sia servita la generazione di investitori di Warren Buffet per ottenere ritorni significativi. In termini di intensità di capitale e cattura del valore, l’AI è molto simile alle ferrovie. Il capex degli hyperscaler è ora stimato tra seicentocinquanta e settecento miliardi per il 2026, la redditività è plausibile solo negli anni 2030, e vi sono forti argomentazioni secondo cui il valore viene catturato dagli utenti finali (e da un sottile livello di abilitatori come chip ed energia), non da chi investe il capitale.
Secondo, il boom dot-com. Le dot-com hanno rappresentato meglio la dinamica di commoditizzazione rispetto alle ferrovie. I binari impiegarono decenni per diventare fungibili tra operatori, mentre molte tecnologie dot-com altamente valutate divennero rapidamente standard e i servizi intercambiabili. L’inferenza AI al livello dei modelli sta diventando sostituibile nel giro di mesi — non completamente, dato che fine-tuning, tooling degli agenti, infrastrutture di valutazione e dati proprietari creano ancora costi di switching reali. Ma abbastanza da far evaporare il potere di prezzo al livello dei modelli molto più rapidamente rispetto a qualsiasi infrastruttura precedente. Per chi guarda alla sostenibilità dei margini delle aziende di modelli AI, l’analogia dot-com è la più calzante. Vale la pena dirlo chiaramente — molti osservatori, tra cui Benedict Evans, descrivono i modelli di base come infrastruttura commodity venduta a costo marginale. Non sorprende quindi che le implementazioni del 2026 parlino sempre più di architetture model-agnostic.
Terzo — e questa è l’analogia rassicurante ma più fuorviante — i semiconduttori. Agli investitori piace questa analogia perché implica che lo strato infrastrutturale catturi valore duraturo grazie a barriere tecnologiche e cicli di qualificazione. Nvidia equivale a Intel, e il resto segue. Ma i semiconduttori avevano cicli di sviluppo pluriennali, tecnologie proprietarie difficili da replicare e lock-in dei clienti su più generazioni di prodotto.
L’AI possiede solo una versione più debole di tutto ciò a livello di chip — il vantaggio di Nvidia è reale ma più limitato — e quasi nulla a livello di modelli, dove oggi si concentra la maggior parte dei capitali.
In altre parole, l’AI è una chimera. Combina un’intensità di capitale da ferrovie con una velocità di commoditizzazione da dot-com e costi di switching da dot-com proprio nel livello dove si concentra la spesa. Questa combinazione non è mai apparsa prima nella storia tecnologica, ed è per questo che ogni analogia risulta parziale. L’implicazione è scomoda — il capitale potrebbe essere distrutto ancora più rapidamente che nelle ferrovie.
Il fatto che gli hyperscaler finanzino questi investimenti con flussi di cassa operativi anziché debito riduce il rischio sistemico ma non cambia la logica della cattura del valore per gli azionisti.
Tornando alla conversazione con family office e investitori: la domanda giusta non è “quale scommessa AI vincerà”, ma “cosa si colloca strutturalmente sopra la curva di commoditizzazione” — applicazioni con dati proprietari, integrazione profonda, workflow regolamentati e verticali con forte distribuzione. L’analogia dei semiconduttori racconta ciò che gli investitori vogliono sentirsi dire, ma non riflette la realtà dove oggi avviene la maggior parte degli investimenti.
Esiste una teoria più ampia che posso discutere caso per caso, ma è troppo lunga per una newsletter.
COSA SIGNIFICA PER L’IMPLEMENTAZIONE DELL’AI IN AZIENDA
La conversazione più utile che stiamo avendo in questo momento con clienti corporate e PMI non riguarda quale modello scegliere. Riguarda invece come progettare un’implementazione AI che non incorpori un errore strutturale a livello architetturale — vale a dire, costruire una forte dipendenza da quel laboratorio che in questo momento è temporaneamente avanti. La matrice sopra suggerisce tre implicazioni a cui continuiamo a tornare nelle sessioni di lavoro.
Primo, il livello dei modelli dovrebbe essere trattato come uno strato di base (substrato), non come strategia. Se la velocità di commoditizzazione dei foundation model si avvicina a costi di switching bassi nell’arco di diciotto-trentasei mesi, allora qualsiasi architettura che “incastra” un singolo fornitore nei propri workflow sta creando un problema futuro. Orchestrazione model-agnostic, inferenza sostituibile e infrastrutture di valutazione che confrontano diversi provider non sono elementi opzionali. Sono una forma di assicurazione strutturale contro il rischio di trovarsi dalla parte sbagliata di un crollo dei prezzi — o, allo stesso modo, di non riuscire a cambiare quando il prossimo modello più potente verrà lanciato a metà costo.
Secondo, il valore risiede nel livello di integrazione, non nel prompt. I clienti che stanno ottenendo guadagni di produttività duraturi dall’AI non sono quelli con le librerie di prompt più sofisticate. Sono quelli che hanno svolto il lavoro meno visibile: pulire i dati interni, mappare i workflow in cui l’AI genera valore reale (rispetto a quelli in cui appare solo impressionante in una demo) e costruire cicli di feedback che permettono agli esperti di dominio di correggere gli output su larga scala. Questa è la parte che oggi il mercato della consulenza tende a sottovalutare, anche perché è più difficile da vendere rispetto a una presentazione di “strategia GenAI”. Abbiamo visto aziende industriali di medie dimensioni generare più valore da un progetto di integrazione dati di sei settimane che da dodici mesi di sperimentazione sui modelli.
Terzo — ed è il punto che richiede più resistenza nelle discussioni con i clienti — attenzione a non pagare prezzi da laboratorio di frontiera per lavori che non lo sono. Una parte significativa dei casi d’uso aziendali dell’AI (classificazione documentale, estrazione strutturata, sintesi, Q&A interno) non richiede capacità di massimo livello. Il divario di costo per token tra modelli di frontiera e modelli open o mid-tier “sufficientemente buoni” può arrivare a uno o due ordini di grandezza in alcuni casi. Una disciplina negli acquisti che si chiede “questo task richiede davvero capacità di frontiera o stiamo pagando per qualcosa che non utilizziamo?” tende a portare a un ROI più rapido. E ha anche il vantaggio aggiuntivo, alla luce della matrice sopra, di ridurre l’esposizione allo strato in cui i margini sono più probabilmente destinati a essere erosi dalla competizione.
Nel complesso, l’immagine di un programma AI aziendale nel 2026 è, a nostro avviso, meno eroica di quanto suggeriscano le slide di consulenza e più “noiosa” nel modo giusto. Multi-vendor per impostazione predefinita. Dati e workflow prima, modello dopo. Disciplina nello scegliere quali casi d’uso giustifichino quale livello di capacità. Le aziende che vediamo farlo correttamente sono, per lo più, quelle che non generano copertura mediatica.
LA POSIZIONE EUROPEA — SOTTOINVESTITA, E QUESTA VOLTA PROBABILMENTE NEL GIUSTO
L’Europa è stata spesso oggetto di critiche — anche da parte dei suoi stessi commentatori — per non aver prodotto un laboratorio AI di frontiera. In particolare, il caso tedesco — dove Mittelstand, regolatori e enti di finanziamento pubblici si sono mossi con la loro consueta prudenza — è diventato quasi una battuta ricorrente nei circoli VC transatlantici. Noi siamo stati meno convinti da questa narrativa.
Se la matrice sopra è corretta, lo strato in cui l’Europa è strutturalmente più debole (training dei modelli di frontiera, capex degli hyperscaler) è anche quello in cui i ritorni privati sono probabilmente peggiori. Lo strato in cui l’Europa è relativamente più forte — AI applicata in settori regolamentati, automazione dei processi industriali, SaaS verticali con forte integrazione nei workflow esistenti — è esattamente quello in cui l’architettura della cattura del valore è meno penalizzante per gli investitori. Questo non significa una piena validazione della politica industriale europea, che è un tema separato e molto più complesso. Ma la conclusione automatica che l’Europa “abbia perso l’AI” presuppone che lo strato che riceve più capitale sia anche quello che genera i maggiori ritorni. La matrice suggerisce che probabilmente non è così.
In arrivo nella prossima newsletter...
Ma, come per molte cose in Europa, la situazione è complessa. La prossima edizione affronterà un vincolo che si colloca a monte degli argomenti finanziari sopra esposti: la domanda energetica dell’AI.
Si prevede che la domanda energetica totale dell’AI cresca di cinque volte entro il 2030, con i carichi di lavoro AI che rappresenteranno il 24% di tutta la capacità dei data center entro la fine del decennio. Il costo energetico deriva da due vettori distinti: il consumo operativo diretto, certo, ma anche i costi indiretti della rete — ossia gli aumenti strutturali dei prezzi dell’elettricità causati dalla crescita esplosiva dei data center AI che competono per la capacità della rete, con effetti su tutte le aziende, indipendentemente dal fatto che utilizzino o meno l’AI. Il differenziale dei prezzi dell’elettricità in Europa aggiunge una complicazione specifica alla lettura ottimistica della sezione precedente. Maggiori dettagli su tutto questo nella prosima etizione della newsletter.
Grafico
Il lavoro di Paul Kedrosky "Honey, AI Capex is Eating the Economy" contiene il grafico che sostiene in modo più efficace l’argomentazione sopra — il capex dei data center AI come quota del PIL degli Stati Uniti, confrontato con il boom ferroviario degli anni 1880 e con lo sviluppo delle telecomunicazioni della fine degli anni ’90 (nel grafico utilizza il 2020). Il punto chiave visivo è che il capex dell’AI (rappresentato dal capex dei data center AI), pari a circa l’1,2 percento del PIL USA e in crescita, ha già superato il picco dello sviluppo delle telecomunicazioni (circa 1,0 percento) e si sta avvicinando a un quinto del picco delle ferrovie (circa 6 percento), con un ciclo di ammortamento degli asset AI significativamente più breve rispetto a entrambi i confronti storici.
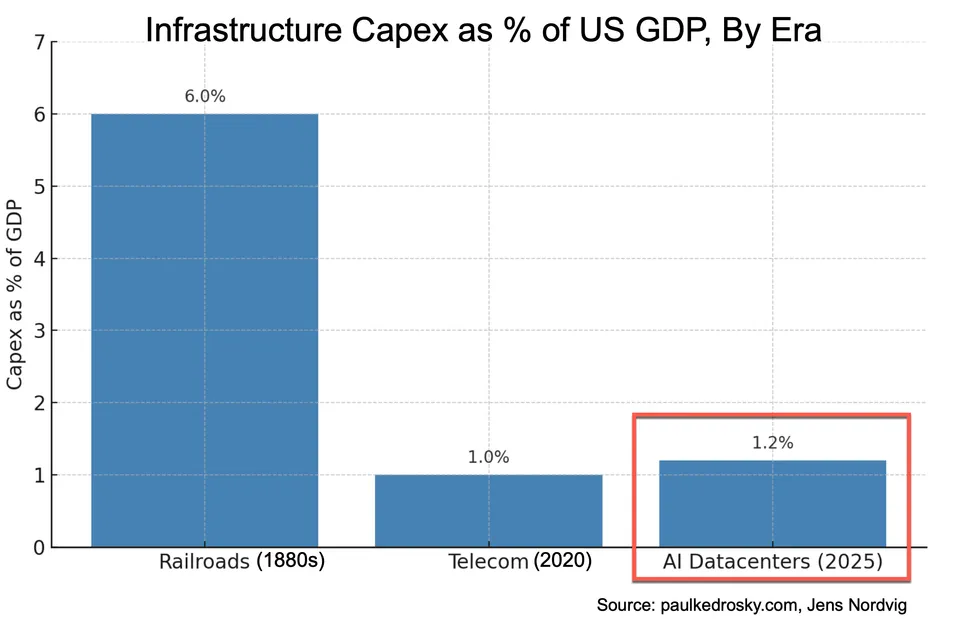
Una nota successiva di Kedrosky del marzo 2026 — secondo cui il capex AI ha contribuito praticamente a tutta la crescita del PIL USA nel quarto trimestre del 2025 — rappresenta il lato macro della stessa dinamica. Il grafico è, a mio avviso, il miglior punto di ingresso su una sola pagina al dibattito tra bolla e boom che abbia visto finora.
Letture
1 — David Cahn, Sequoia Capital, "AI's $600B Question" — il calcolo approssimativo che ha dato il via alla discussione seria sul rapporto tra capex e ricavi nel 2024. L’impostazione si è dimostrata sorprendentemente solida anche con il peggioramento dei numeri. Da leggere insieme alla partecipazione di Cahn al podcast Gradient Dissent di gennaio 2025, dove rivede i calcoli dopo DeepSeek e Stargate.
2 — Jim Covello, Goldman Sachs, "Gen AI: Too Much Spend, Too Little Benefit?" — il classico report ribassista lato sell-side. Il punto più forte di Covello è che problemi complessi richiedono capacità che i modelli attuali non possiedono e che i costi potrebbero non ridursi come previsto. Utile come riferimento anche se non si condivide la conclusione. Interessante anche il fatto che Covello sostenga che la tecnologia non sia strutturalmente progettata per il ragionamento complesso.
3 — Benedict Evans, "How will OpenAI compete?" — il saggio breve più preciso sul perché il livello dei modelli appare strutturalmente più debole rispetto a quanto suggeriscano le valutazioni dei laboratori. L’idea di Evans dei modelli di base come infrastruttura sempre più commoditizzata rappresenta la migliore sintesi della componente “dot-com” della matrice sopra.
4 — Intervista di Ben Thompson a Benedict Evans, Stratechery — la versione più estesa e discorsiva del tema. Particolarmente utile per la discussione su dove si cattura il valore lungo lo stack. Da leggere insieme alla presentazione di Evans "AI eats the world" dell’autunno 2025.
5 — Paul Kedrosky, "Honey, AI Capex is Eating the Economy" — citato sopra per il grafico, ma anche per l’analisi che rappresenta una delle migliori letture macro sul buildout dell’AI, con il giusto livello di cautela sui cicli di ammortamento. La sua nota di marzo 2026 sul contributo del capex AI alla crescita del PIL nel Q4 è il complemento naturale.
6 — Sparkline Capital, "Surviving the AI Capex Boom" — l’analisi più rigorosa in ottica value-investing del ciclo, con un forte confronto storico su come i precedenti boom di capex abbiano influenzato i rendimenti degli azionisti nelle infrastrutture. L’argomento del ciclo del capitale (Edward Chancellor) è quello che dovrebbe accompagnare qualsiasi revisione di portafoglio AI oggi nei family office.


Schreibe einen Kommentar
Achten Sie darauf, die erforderlichen Informationen einzugeben (mit Stern * gekennzeichnet).
HTML-Code ist nicht erlaubt.